
Welcome back to our Inside ScannerPro series, where we dive into the engineering challenges behind building a world-class mobile scanning app. In our previous article, we explored how ScannerPro detects document borders in real time. Today, we’re taking a closer look at two equally critical parts of the image pipeline: shadow removal and color document enhancement.
Why It Matters: Lighting and Legibility
Real-world scans rarely happen under ideal lighting. Users scan documents under desk lamps, near windows, or even outdoors. These conditions often introduce shadows and inconsistent illumination.
These visual artifacts not only degrade readability but also affect downstream features like OCR and PDF archival. That’s why building robust shadow removal and color normalization algorithms was a top priority for us.

Shadow Removal
When scanning documents under ambient light, especially with handheld mobile devices, shadows are almost inevitable. Hands, uneven lighting, and reflections create complex artifacts that degrade the visual quality of scans and impact downstream features like OCR.
We evaluated several traditional methods early on, including global histogram equalization and Retinex-based correction. However, in real-world mobile scenarios, these often destroyed local detail, introduced noise, or required constant tuning to adapt to different lighting conditions.
Rather than trying to blindly “enhance” the image, we pursued a different idea: model the illumination background, separate it from the actual content, and reconstruct a corrected version. We assumed that document surfaces behave approximately like Lambertian reflectors, meaning the observed pixel intensity is proportional to the product of the surface reflectance and the local illumination.
Based on this, once we estimate the illumination background B(x, y), we can recover a corrected image I corrected using the relation:
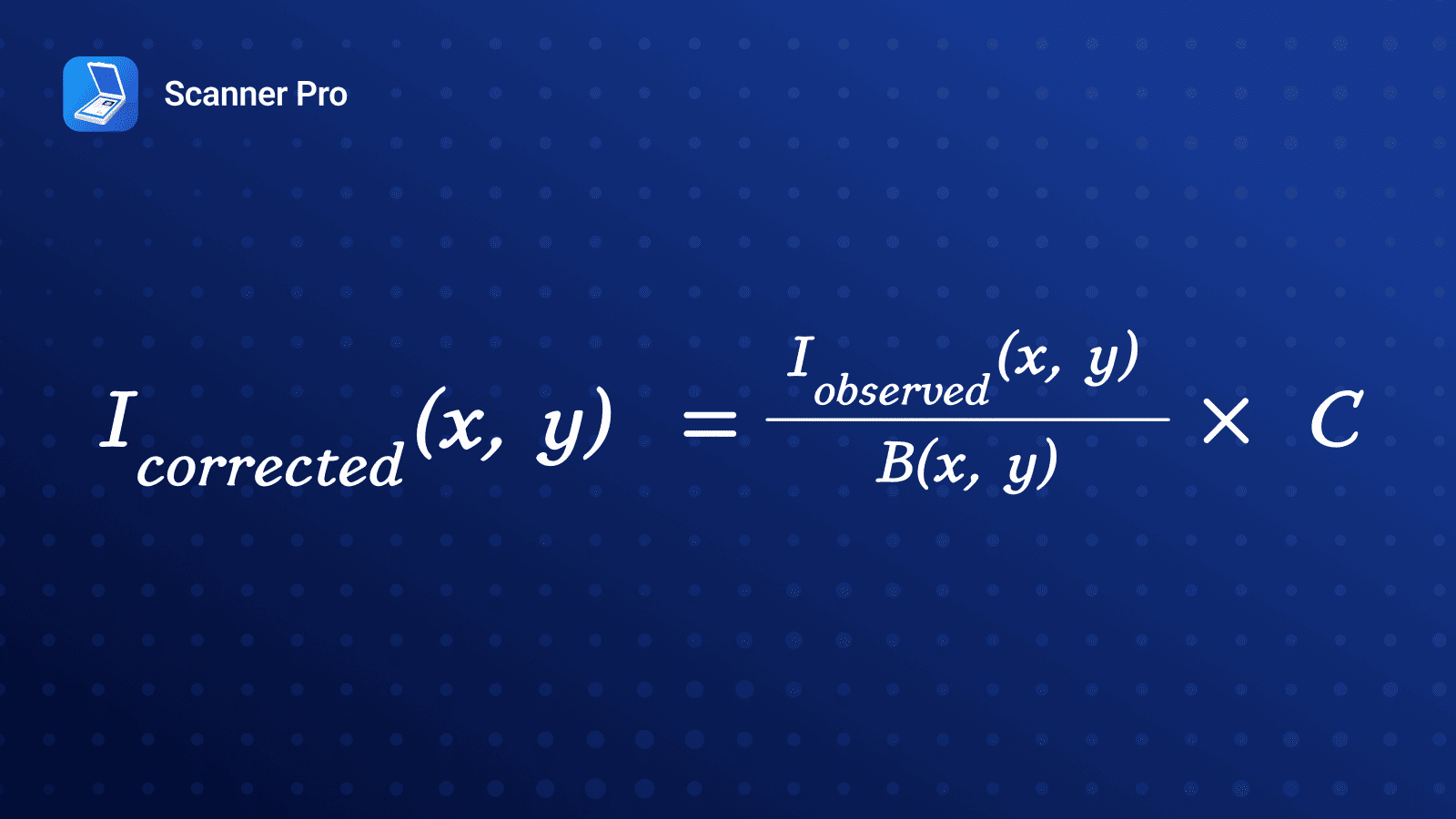 Where C is a constant scaling factor (e.g., target brightness).
Where C is a constant scaling factor (e.g., target brightness).
This reconstruction relies on simulating smooth, low-frequency lighting across the page, which sounds simple in theory but is surprisingly delicate in practice. We needed to find a way to implement this reliably across wildly different lighting conditions and documents.
We faced a critical decision at this point: should we train a deep learning model to predict the background layer, or hand-craft an algorithm ourselves?
Example result from illumination background estimation:
 The First Steps Toward Shadow-Free Scans
The First Steps Toward Shadow-Free Scans
When we began working on shadow removal, deep learning wasn’t a viable path. We lacked a high-quality, diverse dataset of real-world documents with shadow annotations. More importantly, we needed something transparent, debuggable, and deterministic — especially during early iterations.
Our first working prototype visual results were surprisingly good: realistic lighting correction even under directional light, and with no need for learned priors.
But…
Problem #1: Too Slow for Mobile
The downside was performance. The algorithm relied on many small updates to gradually refine the illumination map. On a full-resolution 4032×3024 image, running this on the mobile CPU took ~10 seconds per frame — clearly unacceptable for a real-time or near-instant scanning experience.
Step 1: Bring It to the GPU
Fortunately, the algorithm had a structural advantage: each region of the image could be processed independently. That meant it could be parallelized efficiently — a perfect match for the GPU.
We ported the entire shadow removal pipeline to Metal.
This alone brought performance down from 10 seconds → ~5 seconds per full-resolution image. A significant win, but still far off from our ~400 ms budget.
Step 2: GPU-Level Refinements
We noticed some key inefficiencies:
1. Full-resolution processing was wasteful
There’s no need to start from the highest resolution. Most of the illumination structure is low-frequency, so we introduced a coarse-to-fine mipmap traversal:
- Start at a coarse level (e.g., 32×32)
- Run the illumination estimation algorithm
- Upsample the result as an initial guess for the next finer level
- Repeat until full resolution
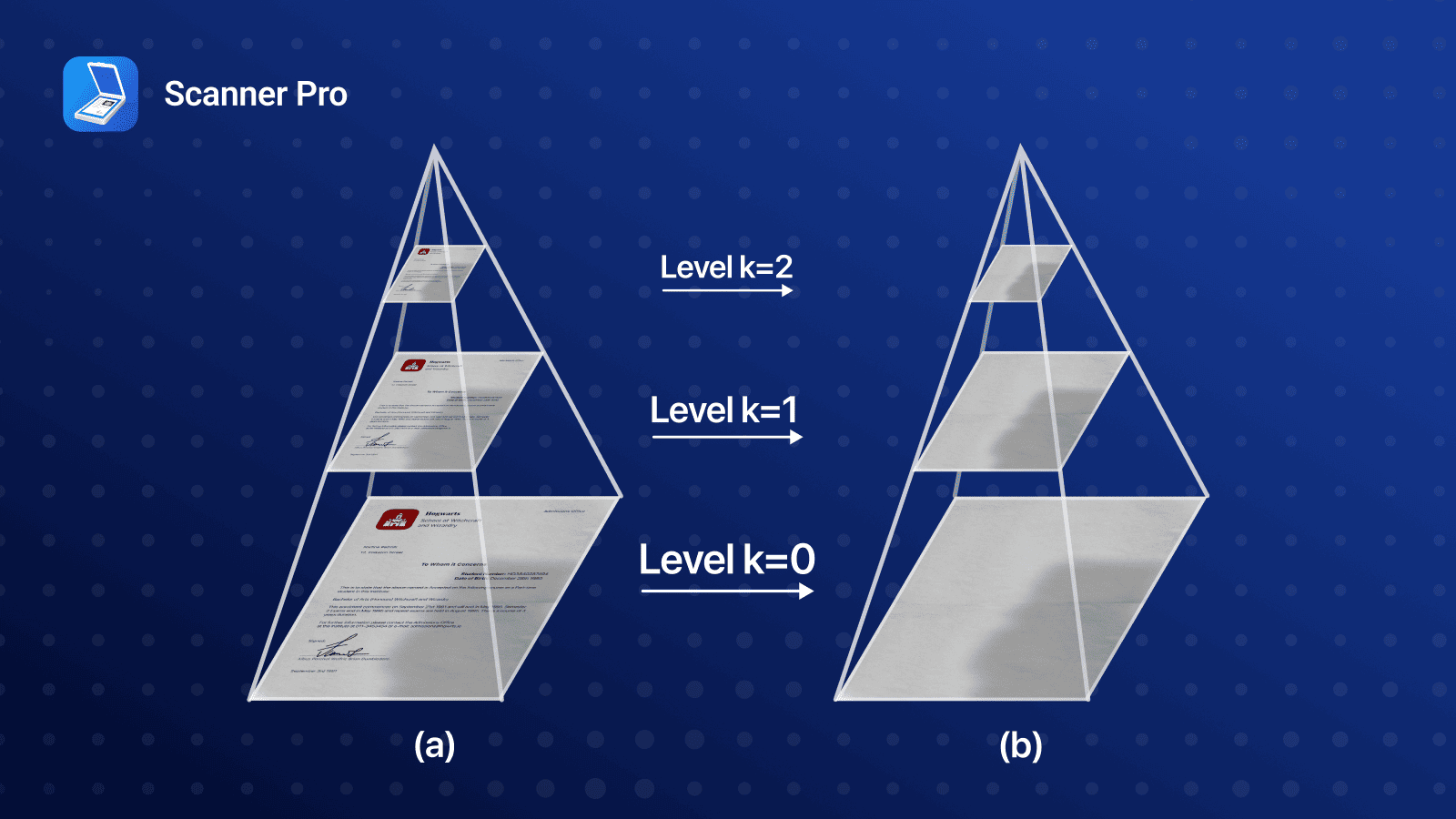 This drastically reduced the overall work time, speeding up the full pipeline.
This drastically reduced the overall work time, speeding up the full pipeline.
2. We were updating already-correct pixels
Even at low resolutions, large parts of the image background (e.g. flat white paper) estimated quickly in early stages. But we kept reprocessing them.
So we added an indicator of whether the background estimate had changed significantly. If not, we skipped that region in subsequent updates. This saved thousands of unnecessary operations, especially on uniform backgrounds.
After solving those bottlenecks, we focused on final refinement and stability.
Alignment Correction
Once we implemented multi-level propagation, new issues appeared.
In corner cases — like complex folds, curved pages, or highly textured backgrounds — we started seeing:
- Ringing artifacts around text
- Inconsistent lighting across folds or shadows
It turned out that mipmap propagation could introduce misalignment between levels: small inconsistencies between the coarse estimate and the finer detail. To catch this, we added an alignment verification step:
- Compare corresponding pixels between levels
- If a significant percentage of them differ → trigger a corrective pass
All these efforts reduced the required time from 5 seconds to around 400ms.
Unfortunately, in some cases, the color appearance was altered by shadow removal, making it unsuitable for direct use on color documents. As a result, we limited full shadow removal to black-and-white mode only.

Color Normalization: More Than Just Shadow Removal
Once we had a solid shadow removal pipeline, the next challenge became clear: color documents. Our goal was simple in theory but difficult in practice:
Normalize lighting and color, without compromising the original appearance.
Our color normalization pipeline is structured into three main stages:
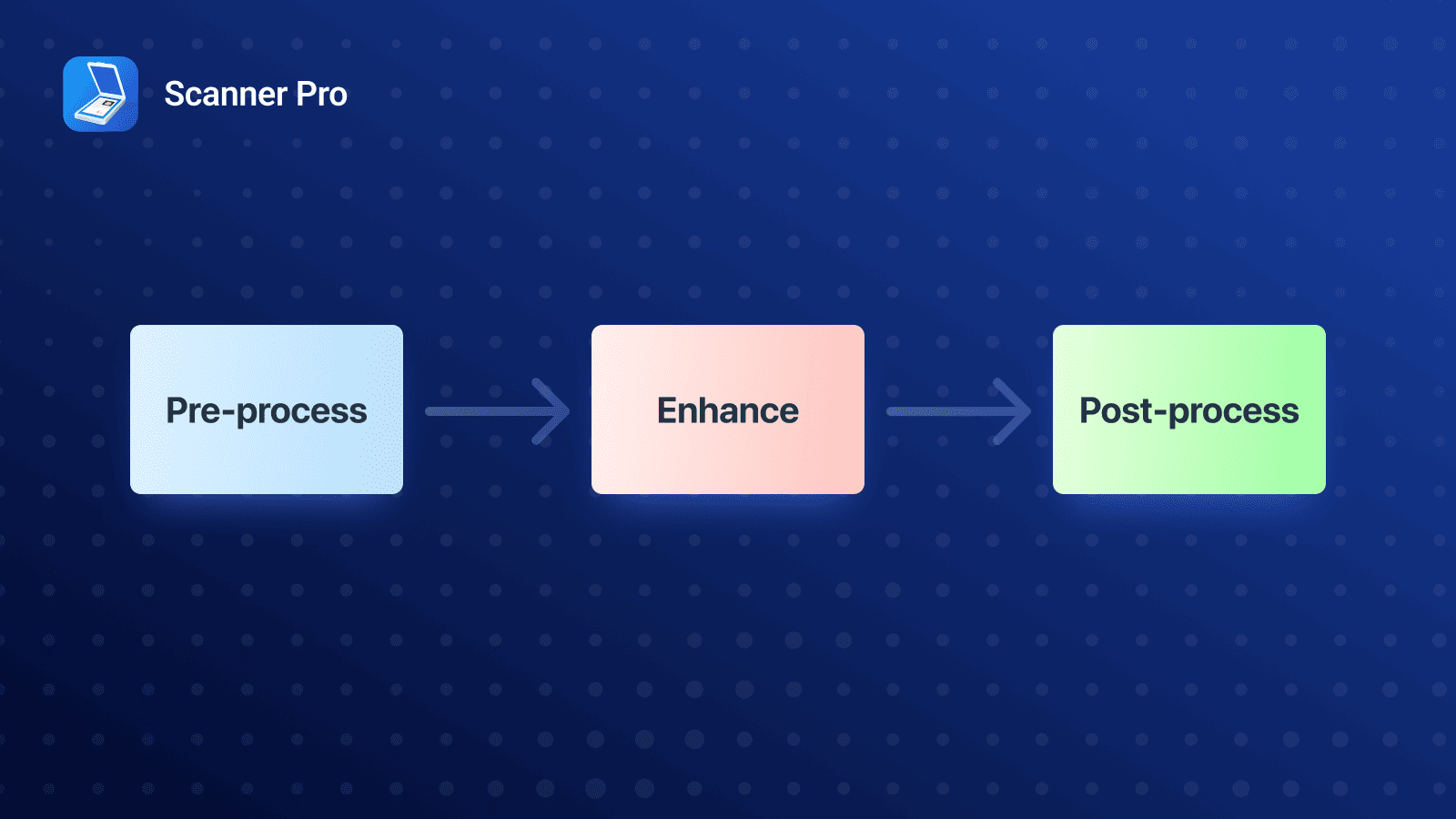 1. Pre-processing
1. Pre-processing
In this initial step, we apply automatic white balancing and extract key image statistics that are used in later stages. This ensures that the enhancement step has all the contextual information it needs up front.
2. Enhancement (Core Stage)
This is the heart of the pipeline. Here, we perform the actual visual corrections, including shadow removal, automatic brightness, and contrast adjustment. These operations work together to normalize lighting while preserving the natural appearance of the document.
3. Post-processing
Finally, we apply localized sharpening, subtle denoising, and other small refinements to improve clarity without introducing artifacts.
While each stage plays a role in the final quality, most of the visual impact comes from the enhancement stage, where we focus on correcting illumination inconsistencies and restoring perceptual balance to the image.
Prioritize Color Retention, Not Perfect Flattening
With color-rich documents, we quickly realized that removing every shadow wasn’t always the right goal.
Elements like logos, stamps, and photographs often appeared in shadowed areas — and aggressively flattening these regions led to washed-out or unnatural color, especially when shadows overlapped with overly saturated color areas.

So we flipped the problem:
Preserve color where it matters, even if that means leaving some shadows behind.
Visually, this tradeoff worked in many cases. It was not ideal, but from product point of view better than one that was flat but dull.
The Challenge: Telling Color From Shadow
This shift brought a new problem: shadows and colored areas can look similar in luminance.
Traditional cues like brightness or contrast were no longer reliable — we needed a way to preserve true color regions while still removing unwanted lighting artifacts elsewhere.
To address this, we implemented a lightweight module that detects color-dense areas, allowing us to selectively exclude them from aggressive normalization and preserve visual fidelity.
We developed a lightweight variant of the shadow removal algorithm: faster, coarser, and tuned to prioritize color fidelity over flattening precision.

Furtures Directions
While our current pipeline works well in most cases, it still struggles with certain edge cases — like complex shadows on textured or colored paper. These limitations stem from the inherent rigidity of classical methods.
Today, with a more diverse internal dataset, we’re in a better position to train lightweight deep learning models for specific tasks like shadow masking, background estimation, and adaptive color normalization. These learned components will help us handle a broader range of document types more accurately while still meeting our performance targets on mobile.
We’ll gradually deploy these models on higher-performance devices, while continuing to use our classical algorithms as a fallback on less capable hardware.
Andrii Denysov, ML Lead Engineer
Scanner Pro is looking for talent to join the team! Watch out for open vacancies and apply.



