Перетворіть відскановані документи на текст, який можна шукати, виділяти, копіювати та експортувати
Відсканований документ — це просто зображення. Ви бачите текст, але не можете його шукати. Щоб вставити в лист, виберіть фрагмент або скопіюйте номер телефону, але для цього його потрібно ввести вручну. OCR — оптичне розпізнавання символів — вносить зміни. Функція розпізнавання тексту в Scanner Pro зчитує текст у ваших сканах і додає шар, який можна шукати, тож ви можете вибирати, копіювати та ділитися вмістом безпосередньо з будь-якого документа в бібліотеці.
Увесь процес відбувається на вашому пристрої. Жодні дані документа не надсилаються на жоден сервер — це важливо, якщо ви регулярно скануєте договори, медичні записи, фінансові звіти чи будь-які конфіденційні матеріали. Для тих, хто керує більш ніж кількома сканами, саме це перетворює Scanner Pro з камери на систему документів.
Розпізнавання тексту доступне більш ніж 30 мовами та потребує підписки Scanner Pro Plus для нових користувачів.
Як вибрати мову для розпізнавання тексту
Scanner Pro за замовчуванням автоматично розпізнає мови на основі латини, зокрема англійську, німецьку та італійську, а інші виявляє без жодного налаштування. Якщо ви скануєте документи текстом не латини, спочатку потрібно налаштувати мову.
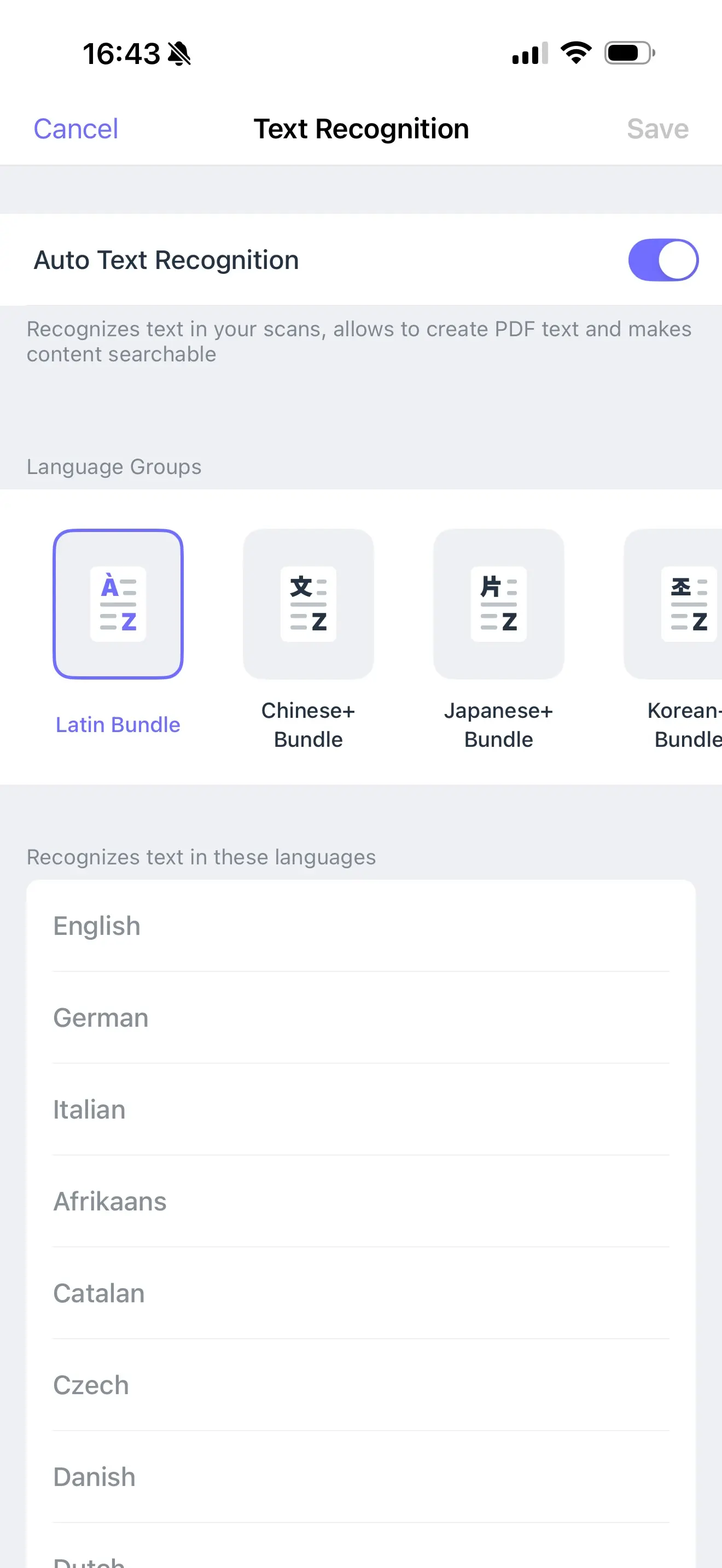
Щоб перемкнутися на іншу мову:
- Відкрийте Scanner Pro і перейдіть до Налаштувань
- Натисніть Розпізнавання тексту (OCR)
- Переконайтеся, що перемикач Авторозпізнавання увімкнено
- Оберіть відповідну групу мови: Chinese+, Japanese+, Korean+, Cyrillic або Інше (включає грецьку)
- Натисніть Зберегти у верхньому правому куті
Після збереження Scanner Pro використовуватиме цю групу мови для всіх нових сканів, доки ви знову не зміните налаштування.
Як розпізнати, скопіювати та поширити текст
- Відкрийте будь-який скан і натисніть Текст у нижній панелі інструментів
- Виберіть один із двох варіантів перегляду у верхній частині екрана:
- Документ — ваш початковий скан із накладеним текстовим шаром. Підходить для читання в контексті
- Текст — лише витягнений текст без початкового розмітлення. Підходить для копіювання або експорту чистого вмісту
- Якщо мова скану відрізняється від ваших поточних налаштувань, натисніть Мова в нижній панелі інструментів і виберіть правильну:
- Для мови на основі латини переконайтеся, що вибрано пакет мови на основі латини
- Для мови не латини, яка відрізняється від налаштування за замовчуванням, виберіть правильний пакет мови та натисніть Перезапустити

- У будь-якому перегляді ви можете виділити певну частину тексту. Натисніть Скопіювати все у нижній панелі інструментів, щоб забрати все одразу, або натисніть Експортувати, щоб надіслати текстовий шар до іншого застосунку
- Коли закінчите, натисніть Готово у верхньому правому куті

Пошук у всіх ваших сканах
Після того як OCR обробить ваші документи, ви зможете шукати у всій бібліотеці — не лише за назвами файлів, а й у реальному вмісті кожного скану.
Щоб знайти у всій бібліотеці: натисніть значок пошуку в перегляді «Мої скани» та введіть запит. Scanner Pro показує результати для всіх документів і підсвічує сторінку, на якій є збіг.
Щоб виконати пошук у певному документі: відкрийте скан і натисніть Пошук у нижній панелі інструментів. Скористайтеся кнопками навігації, щоб переходити між збігами, а потім натисніть Готово, коли закінчите.
Ось тут OCR і стає справді корисним. Бібліотека з 200 сканів перетворюється на те, що можна реально переглядати та шукати. Ви можете знайти назву клієнта, пункт договору або номер рахунка за лічені секунди.
Поради для кращих результатів під час розпізнавання тексту OCR
Скануйте в хорошому освітленні. Точність OCR залежить від якості зображення. Навіть освітлення без різких тіней дає системі розпізнавання найчіткіші вхідні дані для роботи.
Використовуйте режим Ч/Б для документів із великою кількістю тексту. Він створює чистіший контраст, ніж режим «Колір» або «Фото», що зазвичай покращує точність розпізнавання. Ви можете змінити режим кольору після сканування через Редагувати → значок режиму кольору.
Задайте мову перед масовим скануванням. Якщо ви зараз збираєтеся сканувати стопку документів мовою не латини, спочатку налаштуйте групу мови в «Налаштуваннях». Це швидше, ніж потім перезапускати окремі скани.
Одна група мови за раз. Scanner Pro підтримує лише одну активну групу мови не латини одночасно. Для документів із різними мовами за потреби ви можете перезапустити обробку з іншим пакетом через кнопку Мова у режимі перегляду «Текст».
Чи безпечно використовувати OCR для конфіденційності?
Модель OCR від Scanner Pro працює повністю на пристрої. Розпізнаний текст ніколи не надсилається на сервери Readdle або в жодне хмарне сховище — він залишається на вашому iPhone або iPad. Щоб переглянути повну політику обробки даних, перейдіть у Налаштування → Політика конфіденційності всередині застосунку.
Вилагоджування
Текст не розпізнається.
Перевірте, чи ввімкнено «Авторозпізнавання тексту»: «Налаштування» → «Розпізнавання тексту (OCR)» → переконайтеся, що перемикач увімкнено. Також переконайтеся, що встановлено останню версію застосунку.
Неправильні символи у витягненому тексті.
Ймовірно, не збігається група мови. Відкрийте скан, натисніть Текст → Мова, виберіть правильний пакет і натисніть Перезапустити.
Кнопка «Текст» не відображається.
Розпізнавання тексту потребує підписки Scanner Pro Plus. Користувачам тарифу Free потрібно оновитися, щоб отримати доступ до функції.
Часті запитання
Чи працює OCR з PDF-файлами, які я імпортував, а не лише з документами, відсканованими камерою?
Так. Розпізнавання тексту працює з будь-яким документом у бібліотеці Scanner Pro — незалежно від того, чи ви його сканували, чи імпортували з застосунку «Файли».
Чи змінює розпізнавання тексту мій початковий скан?
Розпізнавання додає невидимий текстовий шар поверх скану — початкове зображення зберігається точно так, як його було зафіксовано. Вкладка «Документ» завжди показує початковий скан із накладеним текстом.
Чи вплине перемикання груп мови на розпізнавання в моїх уже наявних сканах?
Ні. Зміна налаштування мови впливає лише на майбутні скани. Документи, які вже були розпізнані, залишаються доступними для пошуку.
Чи можу я використати OCR для документа, що містить дві різні мови?
Не одночасно. Scanner Pro підтримує лише одну активну групу мови за раз. Для документів із різними мовами ви можете перезапустити обробку з іншими налаштуваннями за допомогою кнопки «Мова» в режимі перегляду «Текст», хоча результати можуть відрізнятися для сильно змішаного вмісту.
Які мови підтримує Scanner Pro?
Понад 30 мов, організованих у групи: мови на основі латини (англійська, німецька, французька, іспанська, італійська та інші) розпізнаються автоматично. Параметри не латини включають Chinese+, Japanese+, Korean+, Cyrillic і Other (Грецька). Повний список доступний у розділі «Налаштування» → «Розпізнавання тексту (OCR)».
Пов’язані функції Scanner Pro
- Імпорт документів — OCR працює з імпортованими PDF-файлами та зображеннями, а не лише з новими сканами
- Перекладач — перекладайте розпізнаний текст більш ніж 20 мовами, не виходячи з застосунку
- Розумні категорії — автоматично сортуйте розпізнані документи за типами, як-от рахунки, квитанції та форми
- Розумні робочі процеси — автоматизуйте OCR як частину багатокрокового процесу сканування
- Параметри експорту — надсилайте текстовий шар як файл TXT або як PDF для пошуку
Почніть використовувати розпізнавання тексту
Відкрийте будь-який скан, натисніть «Текст» — і за лічені секунди ви отримаєте вміст, який можна виділяти, копіювати та знаходити за допомогою пошуку. Для тих, хто керує бібліотекою документів, що постійно поповнюється, це одна з найкорисніших можливостей, які надає Scanner Pro.
Робіть високоякісні скани прямо на ходу
Легко перетворюйте документи на PDF за допомогою iPhone чи iPad. Скануйте квитанції, книги, посвідчення особи, рахунки.