将扫描文档转换为可搜索、可选择、可复制的文本
扫描文档本质上只是图片。 你可以看到文字,但无法搜索它;你也可以选中某段内容以粘贴到电子邮件中,或在不手动输入的情况下复制电话号码。 OCR — 光学字符识别 — 带来改变。 Scanner Pro 的文字识别功能会读取你扫描中的文字,并添加一个可搜索的层,这样你就能直接从资料库中的任意文档选择、复制并分享内容。
整个过程都在你的设备上完成。 不会将任何文档数据发送到服务器;如果你经常扫描合同、医疗记录、财务报表或任何机密内容,这一点尤其重要。 对于任何需要管理不止几次扫描的人来说,它能把 Scanner Pro 从“相机”变成“文档系统”。
文字识别支持 30+ 种语言,新用户需要订阅 Scanner Pro Plus 才可使用。
如何为文字识别选择语言
默认情况下,Scanner Pro 会自动识别基于拉丁字母的语言,如英语、德语和意大利语;其他语言无需任何设置也能检测到。 如果你正在扫描非拉丁文字的文档,首先需要先配置语言。
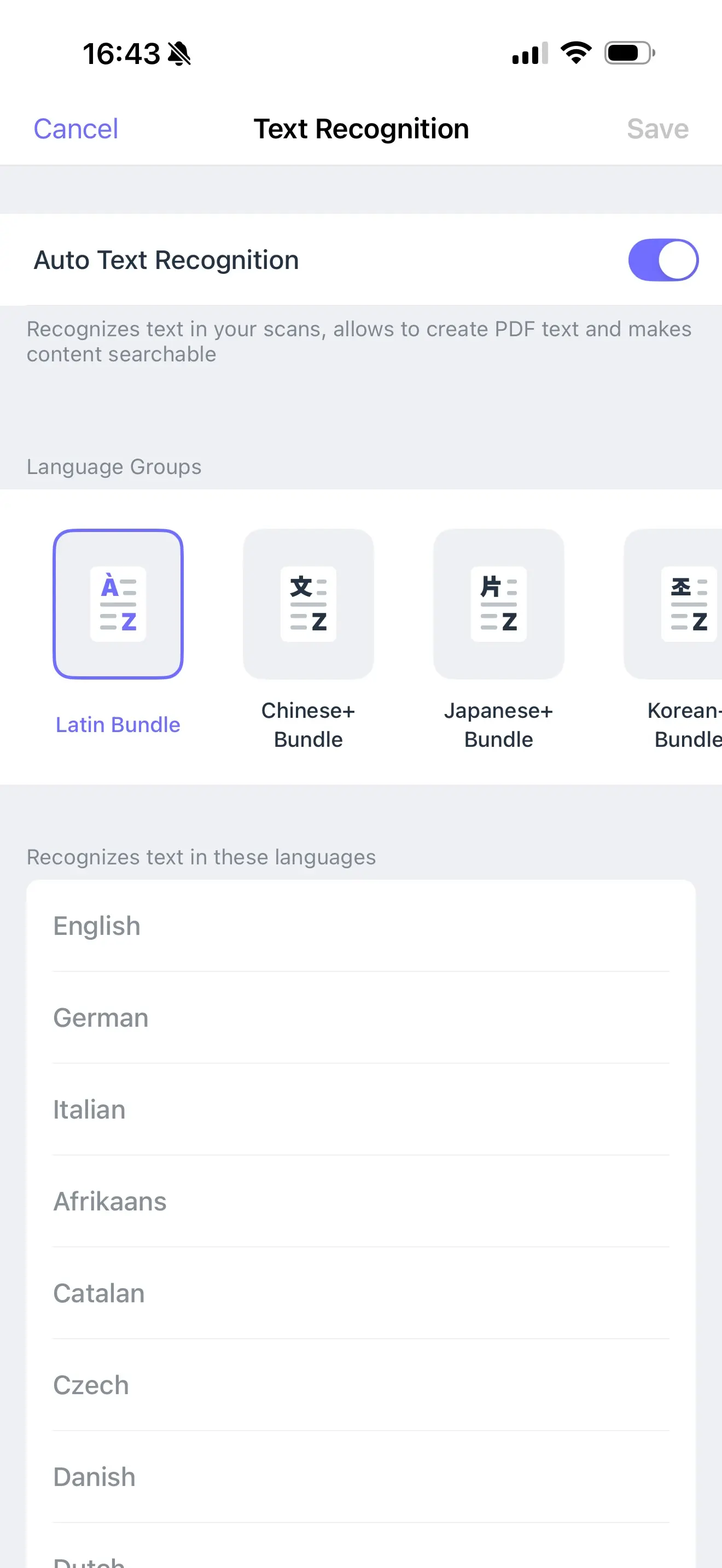
切换到其他语言:
- 打开 Scanner Pro,进入 设置
- 点击 文字识别(OCR)
- 确保已启用 自动文字识别 开关
- 选择合适的语言组:Chinese+、Japanese+、Korean+、Cyrillic 或 Other(其中包括希腊语)
- 点击右上角的 保存
保存后,Scanner Pro 将使用该语言组来处理所有新的扫描,直到你再次更改该设置。
如何识别、复制并分享文本
- 打开任意扫描,然后在底部工具栏中点击 文本
- 屏幕顶部提供两种视图可供选择:
- 文档 — 带有文字层叠加在其上的原始扫描,非常适合在上下文中阅读
- 文本 — 仅提取出的文字,去除了原始版式;适合复制或导出干净的内容
- 如果扫描语言与当前设置不同,请在底部工具栏中点击 语言,并选择正确的语言:
- 对于基于拉丁字母的语言,请确保已选择“基于拉丁字母的语言包”
- 对于与设置默认值不同的非拉丁语言,请选择正确的语言包,然后点击 重新处理

- 在任意视图中,你都可以选择特定的文字内容;点击底部工具栏中的 全部复制 即可一次性获取所有内容,或点击 导出 将文字层发送到其他应用
- 完成后,点击右上角的 完成

跨扫描搜索
OCR 处理完成后,你可以在整个资料库中进行搜索 — 不仅是文件名,还包括每一份扫描的实际内容。
搜索整个资料库:在“我的扫描”视图中点击搜索图标并输入你的查询。 Scanner Pro 会在所有文档中返回结果,并显示包含匹配项的页面。
在特定文档内搜索:打开扫描,然后在底部工具栏中点击 搜索。 使用导航按钮在匹配项之间切换;完成后点击 完成。
这就是 OCR 发挥作用的地方。 200 份扫描构成的资料库,会变成你真的能轻松浏览的内容。 你可以在几秒钟内找到客户名称、合同条款或发票号码。
使用文字识别(OCR)获得更好结果的技巧
在良好光线下扫描。 OCR 的准确性取决于图像质量。 即使没有刺眼的阴影,也能让识别引擎获得最清晰的输入以进行处理。
对文字较多的文档使用黑白模式。 它的对比度比彩色或照片模式更干净,通常能提升识别准确率。 扫描后,你可以通过 编辑 → 颜色模式图标更改颜色模式。
大批量扫描前先设置语言。 如果你准备扫描一叠非拉丁语言的文档,请先在“设置”中配置语言组。 这样比之后逐份重新处理要更快。
一次只用一个语言组。 Scanner Pro 一次只支持一个正在启用的非拉丁语言组。 对于包含多种语言的文档,你可以根据需要在“文本”视图内通过 语言按钮使用不同语言包来重新处理。
使用 OCR 进行识别对隐私安全吗?
Scanner Pro 的 OCR 模型完全在设备端运行。 识别出的文字从不会被上传到 Readdle 的服务器或任何云存储 — 它会一直保留在你的 iPhone 或 iPad 上。 如需查看完整的数据处理政策,请在应用内进入 设置 → 隐私政策 。
故障排除
无法识别文字。
检查是否已启用“自动文字识别”:进入 设置 → 文字识别(OCR)→ 确认开关已打开。 另外,请确保你已安装应用的最新版本。
提取出的文本中出现了错误字符。
很可能是语言组不匹配。 打开扫描,点击“文本”→“语言”,选择正确的语言包,然后点击“重新处理”。
未显示“文本”按钮。
文字识别需要订阅 Scanner Pro Plus。 免费层用户需要升级后才能访问该功能。
常见问题
OCR 适用于我导入的 PDF 吗?还是只适用于我用相机扫描的文档?
可以。 文字识别适用于 Scanner Pro 资料库中的任意文档,无论你是扫描得到的,还是从“文件”应用导入的。
OCR 会改变我原始的扫描吗?
识别会在扫描图像上方添加一个不可见的文字层 — 原始图片会被完全保留为你捕获时的样子。 “文档”选项卡始终会显示带有文字叠加层的原始扫描。
切换语言组会影响我已有的扫描识别结果吗?
不会。 更改语言设置只会影响之后的新扫描。 已识别完成的文档仍可进行搜索。
我能否对包含两种不同语言的文档使用 OCR?
不能同时进行。 Scanner Pro 一次只支持一个正在启用的语言组。 对于包含多种语言的文档,你可以在“文本”视图内使用“语言”按钮,并用不同的设置进行重新处理,不过对于混合内容较多的情况,结果可能会有所不同。
Scanner Pro 支持哪些语言?
30+ 种语言,按组整理:基于拉丁字母的语言(英语、德语、法语、西班牙语、意大利语以及更多)会自动检测。 非拉丁选项包括中文+、日语+、韩语+、西里尔字母以及其他(希腊语)。 完整列表可在“设置”→“文字识别(OCR)”下查看。
相关的 Scanner Pro 功能
- 导入文档 — OCR 适用于导入的 PDF 和图片,不只是新的扫描
- 翻译器 — 将识别出的文本翻译为 20+ 种语言,无需离开应用
- 智能分类 — 自动将识别到的文档按发票、收据和表格等类型分类
- 智能工作流 — 作为多步骤扫描流程的一部分自动化 OCR
- 导出选项 — 以 TXT 文件形式分享文字层,或导出为可搜索的 PDF
开始使用文字识别
打开任意扫描,点击“文本”,你就能在几秒钟内获得可选择、可复制、可搜索的内容。 对于管理不断增长的文档资料库的任何人来说,这是 Scanner Pro 提供的最实用功能之一。