スキャンしたドキュメントを検索でき、コピーできるテキストに変換
スキャンしたドキュメントは、ただの画像です。 テキストは見えますが、検索したり、メールに貼り付けるために一部の文を選択したり、入力せずに電話番号をコピーしたりすることはできません。 OCR — 光学式文字認識 — が変えるもの。 Scanner Proのテキスト認識機能は、スキャン内の文字を読み取り、検索可能なレイヤーを追加します。これにより、ライブラリ内のあらゆるドキュメントから、内容を直接選択・コピー・共有できます。
この処理はすべて、お使いのデバイス上で実行されます。 契約書、診療記録、財務諸表、あるいは機密性の高い情報などを定期的にスキャンする場合でも、ドキュメントデータはサーバーに送信されません。 大量のスキャンを管理する方にとっては、Scanner Proを「カメラ」から「ドキュメント管理システム」に変えてくれるものです。
テキスト認識は30以上の言語に対応しており、新規ユーザーにはScanner Pro Plusのサブスクリプションが必要です。
テキスト認識の言語を選ぶ方法
Scanner Proはデフォルトで、英語、ドイツ語、イタリア語などのラテン文字ベースの言語を自動的に認識します。また、それ以外も設定なしで検出されます。 非ラテン文字のスクリプトで書かれたドキュメントをスキャンする場合は、先に言語を設定する必要があります。
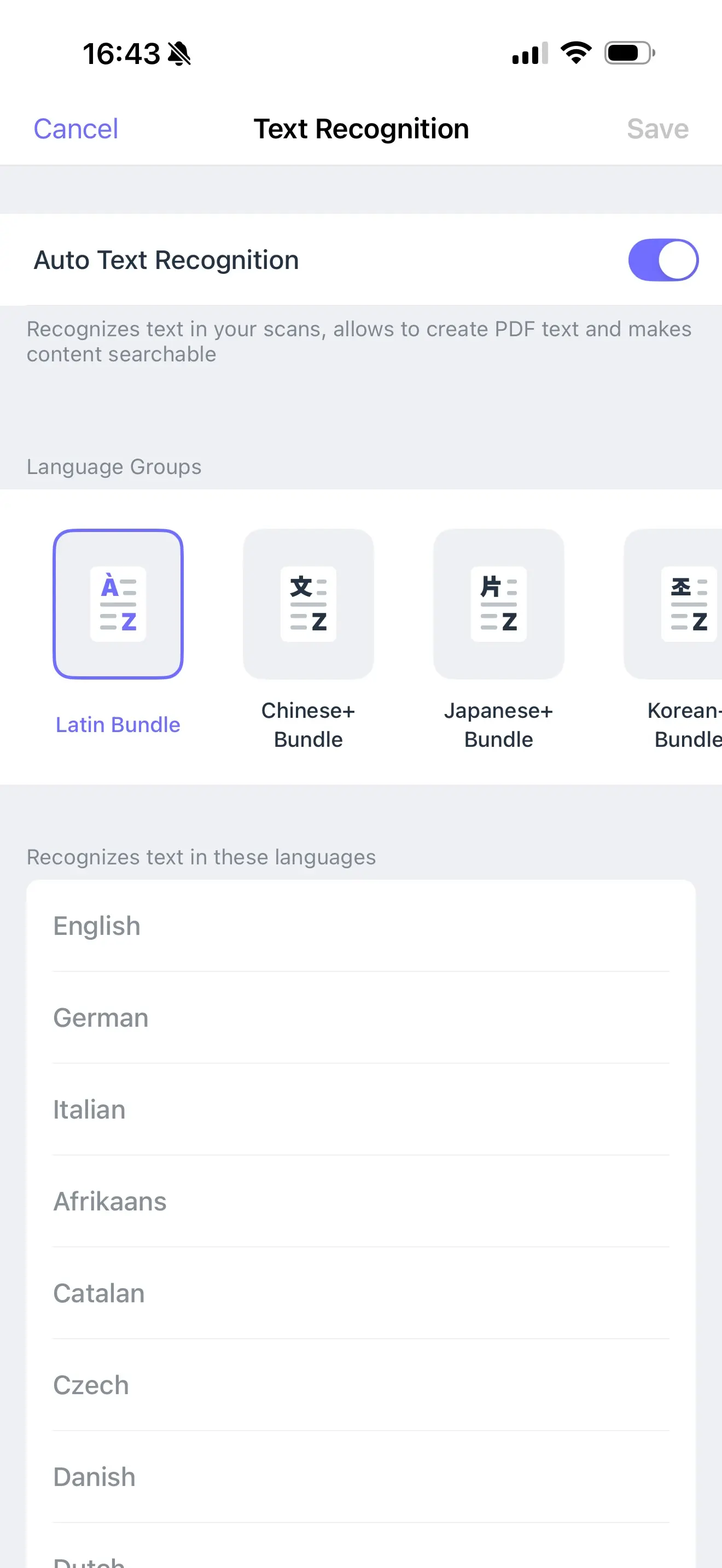
別の言語に切り替えるには:
- Scanner Proを開き、設定に移動します
- テキスト認識(OCR)をタップします
- 自動テキスト認識 の切り替えが有効になっていることを確認します
- 適切な言語グループを選択します:Chinese+、Japanese+、Korean+、Cyrillic、またはOther((ギリシャ語を含む))
- 右上にある保存をタップします
保存すると、設定を変更するまでScanner Proはその言語グループを使って、以降のすべての新しいスキャンを処理します。
テキストを認識して、コピー/共有する方法
- 任意のスキャンを開き、下部ツールバーのテキストをタップします
- 画面上部で、次の2つの表示のどちらかを選びます:
- ドキュメント — 文字レイヤーが重ねられた元のスキャン。文脈を保って読みたいときに便利です
- Text — 抽出されたテキストのみ(元のレイアウトは除去)。きれいな内容をコピーしたり書き出したりするときに便利です
- スキャンの言語が現在の設定と異なる場合は、下部ツールバーの言語をタップして、正しいものを選択します:
- ラテン文字ベースの言語の場合は、ラテン文字ベースの言語バンドルが選択されていることを確認してください
- 設定のデフォルトと異なる非ラテン文字の言語の場合は、正しい言語バンドルを選択して再処理をタップします

- どちらの表示でも、テキストの特定の範囲を選択できます。すべてを一度に取得するには、下部ツールバーのすべてコピー をタップするか、書き出すをタップしてテキストレイヤーを別のアプリに送信します
- 完了したら、右上の完了をタップします

スキャン全体から検索する
OCRがドキュメントを処理したら、ライブラリ全体を検索できます — ファイル名だけでなく、すべてのスキャンの実際の内容を検索できます。
ライブラリ全体を検索する:My Scansの表示で検索アイコンをタップし、検索語を入力します。 Scanner Proはすべてのドキュメントに対して結果を表示し、どのページに一致があるかを示します。
特定のドキュメント内を検索する:スキャンを開き、下部ツールバーの検索をタップします。 ナビゲーションボタンを使って一致箇所を移動し、終わったら完了をタップします。
ここでOCRの価値が発揮されます。 200件のスキャンから、実際に探し回れるものになります。 数秒で、取引先名、契約書の条項、または請求書番号などを見つけられます。
OCRテキスト認識でより良い結果を得るためのヒント
良い照明のもとでスキャンしてください。 OCRの精度は画像の品質に左右されます。 強い影がない均一な照明なら、認識エンジンが最も扱いやすい入力になります。
文字が多いドキュメントには白黒モードを使用。 色(カラー)や写真モードよりもコントラストがはっきりしているため、認識精度が向上することが多いです。 スキャン後は、編集 → 色モードのアイコンから色モードを変更できます。
まとめてスキャンする前に言語を設定します。 非ラテン文字の言語でドキュメントを束でスキャンしようとしている場合は、まず設定で言語グループを構成してください。 その後、個別に再処理するよりも速くなります。
1度に1つの言語グループ。 Scanner Proは、非ラテン文字の言語グループを一度に1つだけ有効にできます。 複数言語が混在するドキュメントの場合は、必要に応じて、テキスト表示内の言語ボタンから別のバンドルで再処理できます。
プライバシーの観点でOCRは安全ですか?
Scanner ProのOCRモデルは、完全にデバイス上で動作します。 認識されたテキストは、Readdleのサーバーやクラウドストレージにアップロードされることはありません — iPhoneまたはiPadに保存されます。 データの取り扱いに関するポリシー全体を確認するには、アプリ内の設定 → プライバシーポリシー にアクセスしてください。
トラブルシューティング
テキストが認識されません
自動テキスト認識が有効になっていることを確認してください:設定 → テキスト認識(OCR) → 切り替えがオンになっているか確認します。 あわせて、最新のアプリバージョンがインストールされていることも確認してください。
抽出されたテキストに誤った文字が含まれています
言語グループが一致していない可能性があります。 スキャンを開き、Text → Languageをタップして正しいバンドルを選択し、Reprocessをタップします。
テキストボタンが表示されません
テキスト認識にはScanner Pro Plusのサブスクリプションが必要です。 無料プランのユーザーは、機能を利用するためにアップグレードが必要です。
よくある質問と答え
カメラでスキャンしたドキュメントだけでなく、インポートしたPDFにもOCRは使えますか?
はい。 テキスト認識は、スキャンしたかFilesアプリから取り込んだかにかかわらず、Scanner Proライブラリ内のあらゆるドキュメントで利用できます。
テキスト認識は元のスキャンを変更しますか?
認識では、スキャンの上に見えないテキストレイヤーが追加されます — 元の画像は、取り込まれたとおりに正確に保持されます。 ドキュメントタブには、テキストのオーバーレイが重ねられた元のスキャンが常に表示されます。
言語グループを切り替えると、既に認識済みのスキャンの認識結果にも影響しますか?
いいえ。 言語設定を変更しても、これから先の新しいスキャンにのみ影響します。 すでに認識されたドキュメントは、検索可能な状態のままです。
2つの異なる言語が含まれるドキュメントに、OCRを使うことはできますか?
同時にはできません。 Scanner Proは、一度に1つの有効な言語グループに対応しています。 複数言語が混在するドキュメントの場合は、テキスト表示内のLanguageボタンから別の設定で再処理できます。ただし、内容が特に混在している場合は結果が異なることがあります。
Scanner Proはどの言語に対応していますか?
30以上の言語に対応。グループに整理されています:ラテン文字ベースの言語(英語、ドイツ語、フランス語、スペイン語、イタリア語など)は自動的に検出されます。 非ラテン文字のオプションには、中国語(Chinese+)、日本語(Japanese+)、韓国語(Korean+)、キリル文字(Cyrillic)、およびOther(Greek)があります。 完全な一覧は、設定 → テキスト認識(OCR)で表示できます。
関連するScanner Proの機能
- ドキュメントを取り込む — OCRは新しいスキャンだけでなく、取り込んだPDFや画像にも対応
- 翻訳 — アプリを離れずに、認識したテキストを20以上の言語に翻訳
- スマートカテゴリ — 認識したドキュメントを、請求書、レシート、フォームなどの種類に自動で分類
- スマートワークフロー — 複数ステップのスキャン手順の一部としてOCRを自動化
- 書き出しオプション — テキストレイヤーをTXTファイルまたは検索可能なPDFとして共有
テキスト認識を始めましょう
任意のスキャンを開いてTextをタップすれば、数秒で選択でき、コピーでき、検索できるコンテンツが使えるようになります。 増えていくドキュメントライブラリを管理している方にとって、Scanner Proが提供する中でも特に役立つ機能の1つです。